So, You’ve Started Tracking Errors. Now What?


Let me start off with a little exercise. Just sit back, close your eyes and let me know if this sounds familiar. Well, maybe you shouldn’t close your eyes.
Anyway, you’ve been working on a project for some time now. Some bugs are reported to you now and then, but you feel something’s off.
You suddenly remember that it would be a good idea to set up some kind of an error tracking system. There are a few choices, like Sentry, Bugsnag, Rollbar and some more. After choosing wisely, you install everything necessary and, lo and behold, some errors are starting to show up!
And now comes the critical part. You promise yourself that you’ll check the error reports periodically and fix them as they come in. If that sounds familiar, chances are that these error reports aren’t getting fixed as diligently as you’d expect.
Now What?
What I just described is the current situation at Productive. Bugs are getting fixed, but the ones that don’t “stand out” are kind of getting overlooked. Another issue is that the error reports are in Bugsnag, so they’re not in your face when you start working on your tasks for the day. As a consequence, our product managers aren’t always aware of the error reports so they can’t plan accordingly.
As part of our team’s internal initiative, for some time now, we’ve been aware that it just isn’t enough to set up an error tracking system. A process around it must exist. Just like with tasks, someone has to be responsible, the level of priority must be evaluated, and the error reports must be considered part of the workload. And now, with more people in our team, we can finally make things right.
In this post, I’ll show you an overview of all the things we’re trying to improve to really get a grip on bugs and errors.
Since we’re currently working on this whole process, some things might change or some new points might get added, but the general idea will still stand.
Defining the Pain Points
First of all, I’ll let you in on a small glimpse into the current state of our Bugsnag:
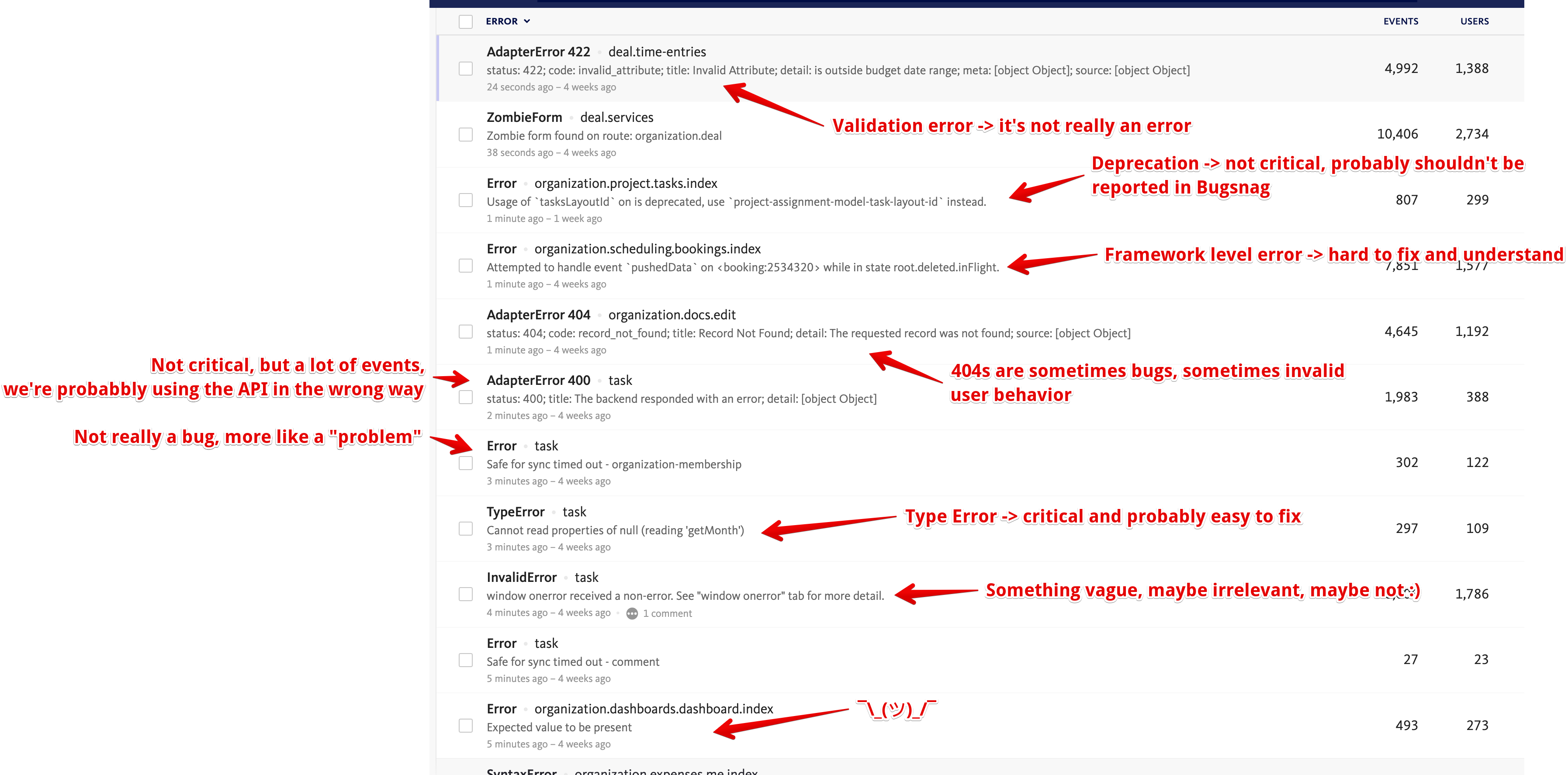
I’m sure this might come as a surprise to some of you, but when you have a lot of users doing all sorts of things in your app, things are bound to go wrong.
Even though this will be improved, as it is—this still gives a lot of information on how to organize a seemingly unrelated bunch of errors.
I’ve briefly mentioned which issues bothered us the most. There were a couple of issues on top of that, which we found out about after running a quick poll between our team members:
- The reported bugs are just posted in a Slack channel, without any categorization and with little filtering
- Sometimes the reported bugs are too vague
- Lots of irrelevant bugs are reported, so there’s a lot of noise
- No one is assigned to the bugs
- The bugs from the latest release aren’t tagged in any significant way
- The code in the bug reports is minified
- Sometimes the bugs are really hard to reproduce and the lack of the additional state of the app at the time makes it even harder to reproduce them
- We’re not sure exactly how many bugs have been dealt with
Now would be a good point to mention that these issues built up over time. Depending on the size of your project/team, the architecture or workflow, some issues might be more important than others. The key here is to find out what is really slowing down your team, but feel free to use this list as an inspiration.
Plan Accordingly
After we’ve identified and written down the actual issues, the team collaboration kicked in and we got a lot of ideas on how to improve our situation.
The first step was to create a plan of attack. Taking all the issues into consideration, we came up with a list of potential solutions that might help us out. Since this was some sort of a brainstorming session, everyone was encouraged to leave their opinions and suggestions.
Doing it this way, we were sure that we covered all the pain points that bothered the very people that were working on the bug reports.
Needless to say, you can’t do all of these things at once. Some priorities came up during the brainstorming session and here’s what we came up with:
Upload the source maps to Bugsnag
Create a solution to sync the bugs from Bugsnag with tasks in Productive
By using webhooks or Bugsnag API, fetch the relevant data from Bugsnag and send it to Productive
Find a way to categorize, prioritize and assign the bugs to the correct team members
Define who the correct team members are, so they can resolve or delegate the bug
Categorize the bug according to the route where the error occurred (until we accompany the bugs with relevant metadata)
Notify the assigned team members of the reported bug
Set the priority based on the number of occurrences
Send additional metadata for each bug to ease the reproduction process
Filter out irrelevant bugs (like one-offs and similar)
Find a way to automate deleting old or stale bug reports
Decide on a threshold for the notifications
This relates to the second point
Ease the process of generating a report for fixed/reported bugs
I agree, it’s a big list. There’s a lot to do, but it’s not necessary to finish them all before we can reap the rewards. The most obvious thing was to upload the source maps since it’s not that difficult to do, but will tremendously help out when resolving bugs.
Some of the points are a bit touch-and-go. We’ll set something up, but some parts might change after we get a feel of how everything fits together. This includes the thresholds, automating the deleting process, and a couple of other points.
It’s important to consider the amount of noise one sees when dealing with bugs. We want to minimize the amount of bugs actual humans need to deal with—mostly because we don’t want to get overwhelmed with the sheer number of bugs. Naturally, you have to be careful not to strip out significant and relevant bugs!
Fin?
During our brainstorming session, we thought about our goals for the initiative. We came up with this…
For this to work properly, there are two things that need to be done:
- Have a workflow/process in place for handling bugs
- Get a good Bugsnag set up so that dealing with bugs is as easy as possible
After these are defined, every member of the frontend team should be aware of these processes and do their part to keep the number of bugs at a minimum.
This isn’t some super complex idea, nor is it as profound as I would like it to be. It summarizes the whole initiative in a couple of sentences, but is often overlooked when trying to get on top of this issue.
Doing it this way really does require additional work and will probably drive you out of your mind sometimes, but the payoff is huge! Think about the happier users, how your product will be more robust, and the amount of things you might learn that you weren’t aware of before. And can you really say that you’re tracking errors if you’re not resolving them in due time?
In a product of this size, you’re not going to cover every case that might happen with tests and your coding. This might sound a little demoralizing, but it shouldn’t be, it’s a normal thing! There are a lot of things that can go wrong in building an application, so in order to cover your bases even more, error tracking is a step in the right direction.
If you’re really interested in a particular subject we discussed here briefly, we’ll be posting more deep-dives related to specific implementations of the mentioned solutions, so stay tuned for that!

