Custom Fields: Give Your Customers the Fields They Need


Here at Productive, we’re building an operating system for digital agencies.
But, because each agency is different (think type, size, services they offer, the way they’re set up as an organization…), they need customization options for their workflows. So it’s pretty hard to model all those needs and use cases through a unified data model.
If only there were a way to let them shape those models to their own needs.

Let’s say that one of our customers, ACME digital agency wants to keep track of their employees’ nicknames and to be able to search them by that field. Other than that, they would also like to keep track of their birthdays and be able to sort them and group them by that date.
To me, as a developer, this sounds as simple as it gets—add two new columns to the people table, open those attributes to be editable over the API and send them back in the response.
But should we do that? Should we add all kinds of fields to our models even if those fields are going to be used only by a handful of our customers?
Let me show you how we tackled this type of feature request and made a pretty generic system around it.
What Did Our Customers Want?
It was pretty clear to us what our customers wanted, and that was:
- to be able to add additional fields to some of our models (People, Projects, Tasks, …)
- to have various data types on those fields (text, number, or date)
- to be able to search, sort, or even group by those fields
Our Approach
The Custom Field Model
As we’re building a RESTful API that’s formatted by the JSON:API specification and store our data in a MySQL8 relational database, a few things were pretty straightforward – we need a new model and we’ll name it Custom Field (naming wasn’t an issue here 🥲).
The main attributes of that model should be:
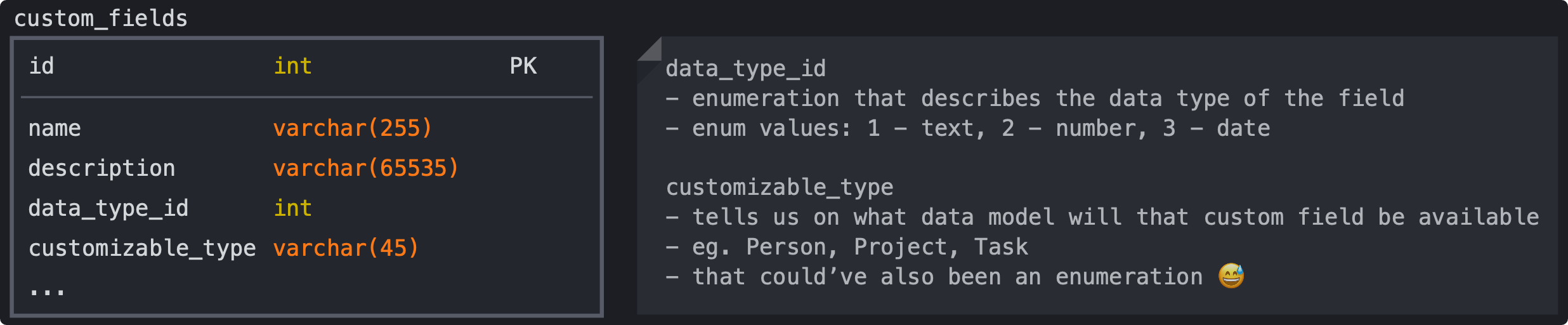
How To Store the Field Values?
OK, so now that we know how to define custom fields, how can we know which value someone assigned to a custom field for some object? And where to store that information?
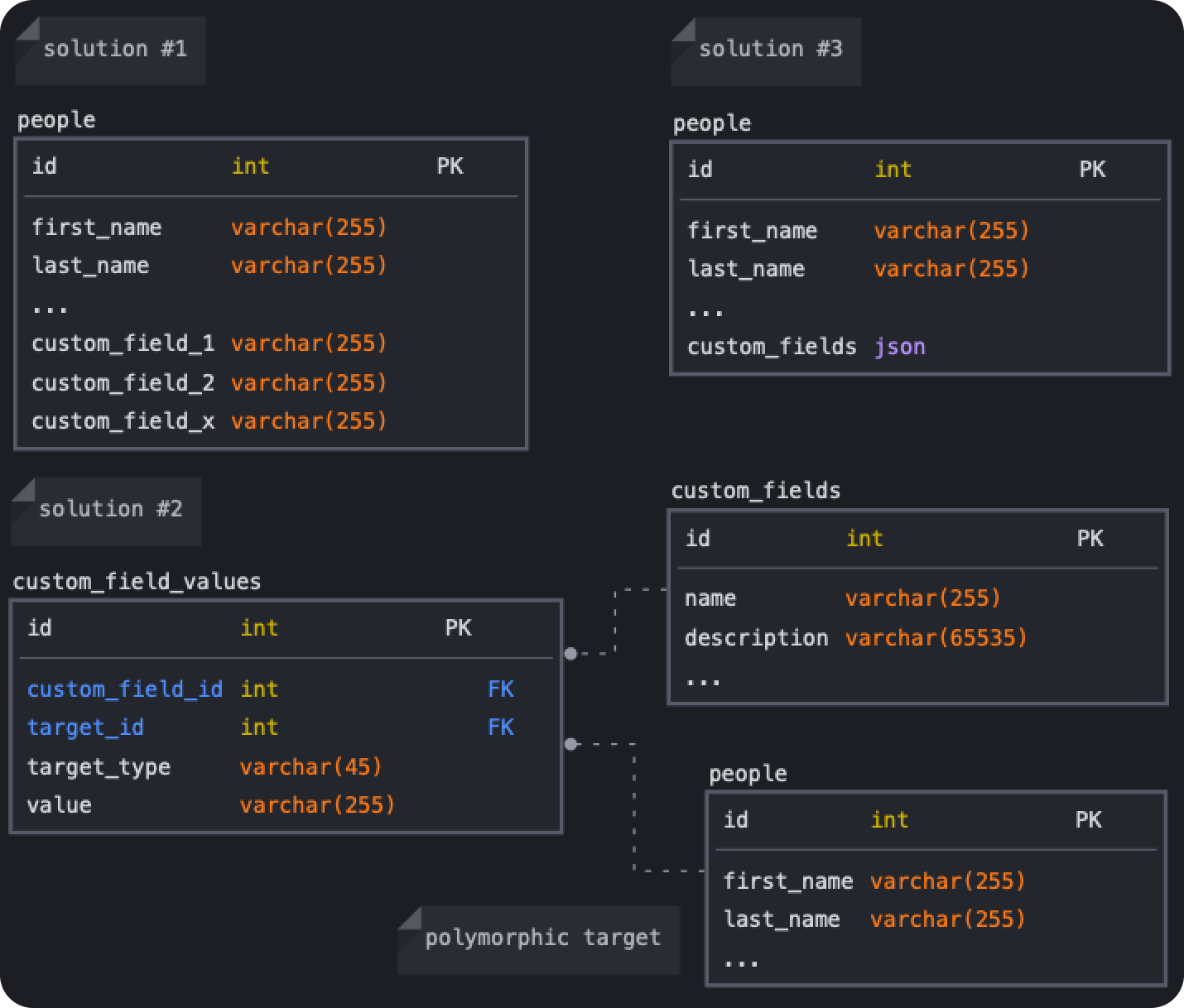
Three possible solutions came to mind:
1. Add a limited number of custom_field columns to our models
We can add a few custom_field columns to our models and that will work for some of our customers but there will always be others that need few extra fields. Adding numerous columns to our models surely isn’t the best solution, we can do better than this 😅
2. Add a join table
As mentioned before, while relying on a relational database, a join table sounds like the go-to approach. That table would be a simple join table between the custom field and a polymorphic target (yay, Rails 🥳). Other than those foreign keys, we would have a column to store the value.
3. Add a single JSON column to our models
This sounded as flexible as it gets. It would be a simple map where the key would be the custom field ID and the value would be the assigned value for that custom field.
Why We Ended Up Choosing JSON
The first solution was just too limited so we discarded that one immediately and focused on the remaining two solutions.
On one hand, a better design would be to have the custom field values represented by a model but on the other hand, we won’t actually do much with that data. That would just be data that our users set on our objects, data that isn’t important for our business logic. So a simple JSON column didn’t sound bad either.
The searching and sorting aspect of this feature request was probably the most important one for us. That was supposed to work as fast as it gets, without being a burden to our performance.
That’s why we implemented both solutions, tested a lot of searching/sorting/grouping scenarios (we’ll go through that in more detail soon), and then checked the metrics.
The faster solution was the second one, the one with the JSON column, and that made sense to us. That solution doesn’t use JOIN clauses in SQL since the values are written directly in the searched table and can be queried in the WHERE clause. Luckily for us, MySQL8 supports a bunch of great functions to work with JSON columns (JSON_EXTRACT, JSON_UNQUOTE, JSON_CONTAINS and others).
Great! Now that we know how to store the custom field values too, let’s dig into the coding.
From a development point of view, we did the following:
- Added a new model, Custom Field, and implemented CRUD operations that can be called over the API
- Wrote schema migrations that added a JSON column –custom_fields – to some of our models (people, projects, tasks, …)
- Opened the custom_fields attribute so it can be edited over the API
- Wrote a generic validation that checks if all the values in the custom_fields hash have the appropriate data type
- Added the custom_fields attribute to the API response of the appropriate models
That was most of the work we needed to do to be able to manage custom fields in our models.
But…what about the searching and sorting aspect of custom fields?
Searching Through Custom Field Values
We already had a generic solution written for searching over the API.
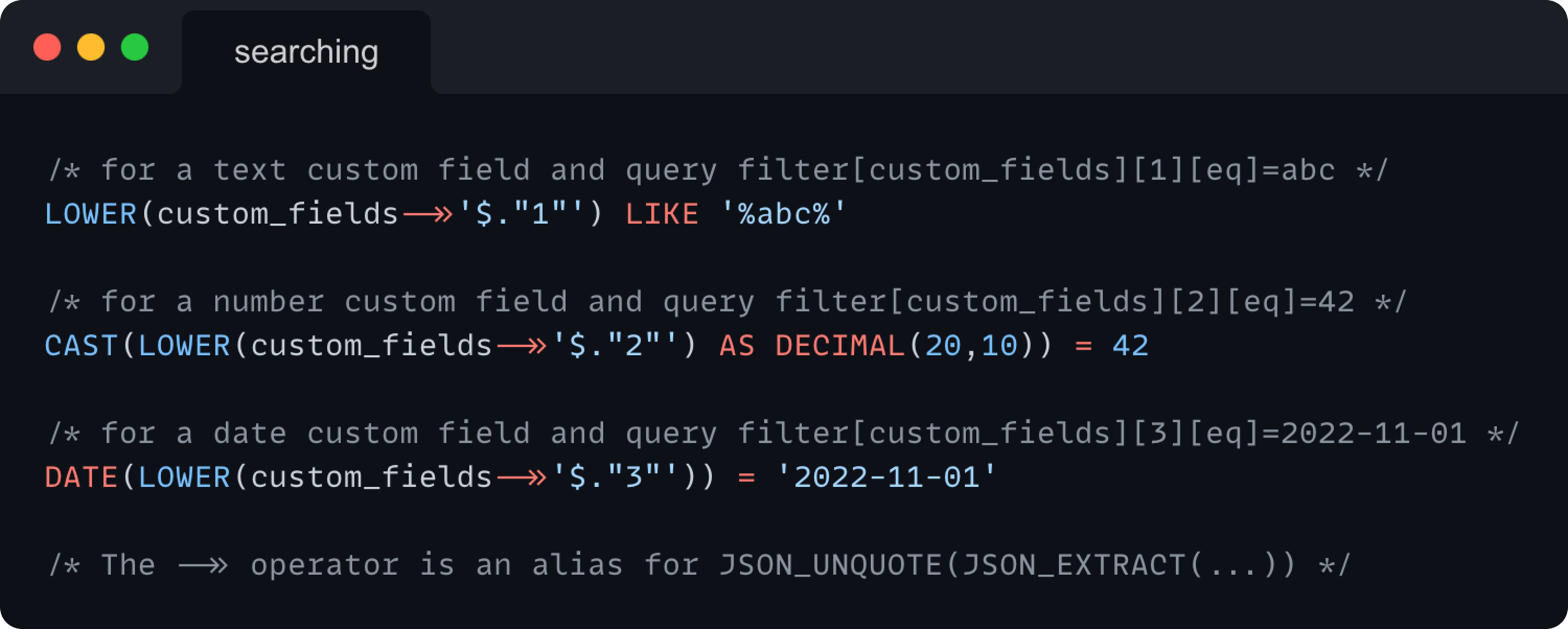
We have a format of sending query params for searching, like filter[attribute][operation]=value. For searching through custom fields, we wanted to keep the same format so we ended with a quite similar one –filter[custom_fields][custom_field_id][operation]=value.
We had to add an if-else statement that would handle the custom fields filtering in a different way than filtering through other attributes as the format contained one additional argument—custom_field_id.
What was different in the filtering logic was that we have to load the custom field that’s being filtered by and check what data type its values are. That’s needed to cast the values into numbers or dates—text values don’t make a difference.
So the query params and its SQL query counterparts, based on custom field type, would look like this:
Sorting by Custom Field Values
The concept of sorting by attributes is something we also already tackled by abstracting logic.
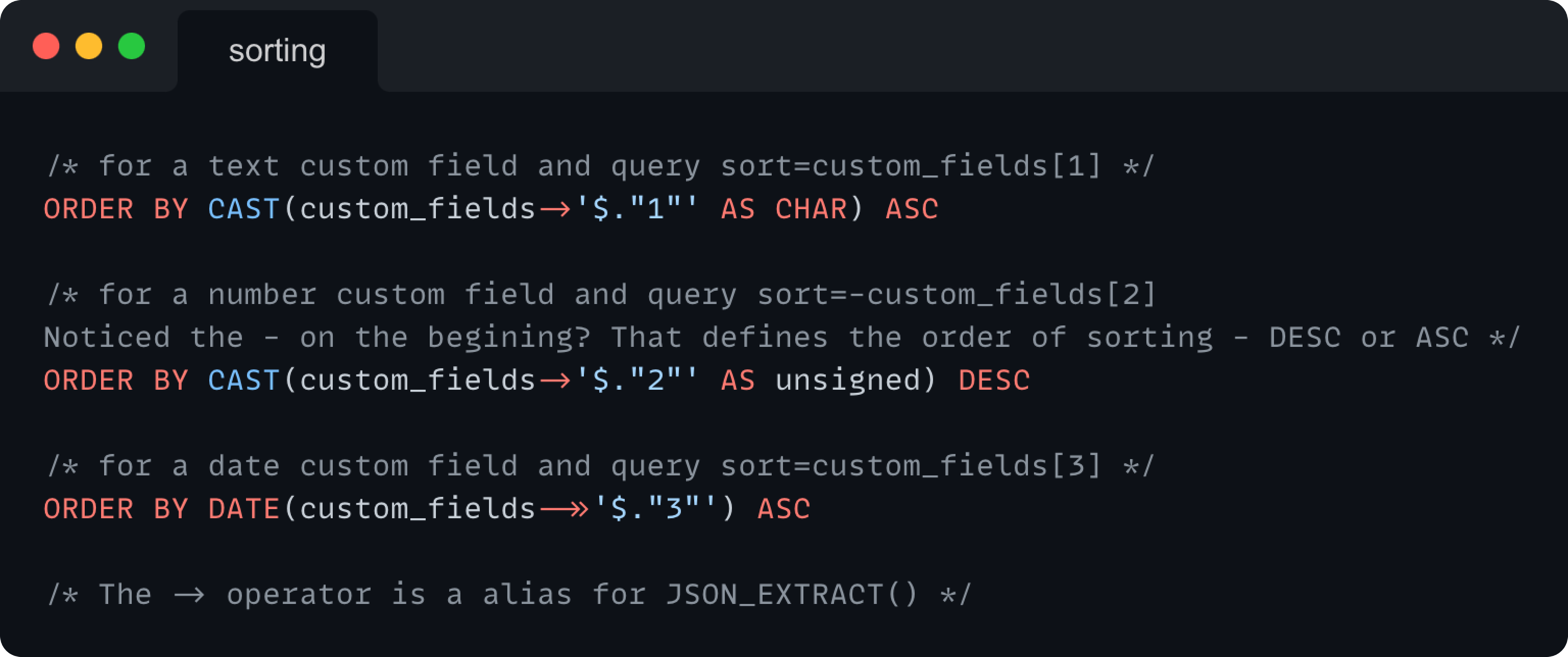
The only thing that changes when sorting by custom fields is that we first need to cast the values and then sort by them.
Once again, there’s a small change in the format for custom fields sorters (sort=custom_fields[custom_field_id]) compared to when sorting by a standard attribute (sort=attribute). We need to handle the custom_fields sorters separately because we have to load the desired custom_field and check its type.
Then the ORDER BY statement, based on custom field types, looks like this:
Grouping by Custom Field Values
This was a fun one. The main point here was that you should include the custom fields as some kind of columns stated in the SELECT statement so that you could later use those columns in the GROUP BY statement.
To get the custom field in the SELECT statement, you have to create a virtual column for it. All we needed to do was to extract the values of the grouped custom field and give that virtual column an alias so that we could reference it in the GROUP BY statement. For the column alias we went with the format custom_fields_{custom_field_id}.
For a custom field with id=x, this is done as following:
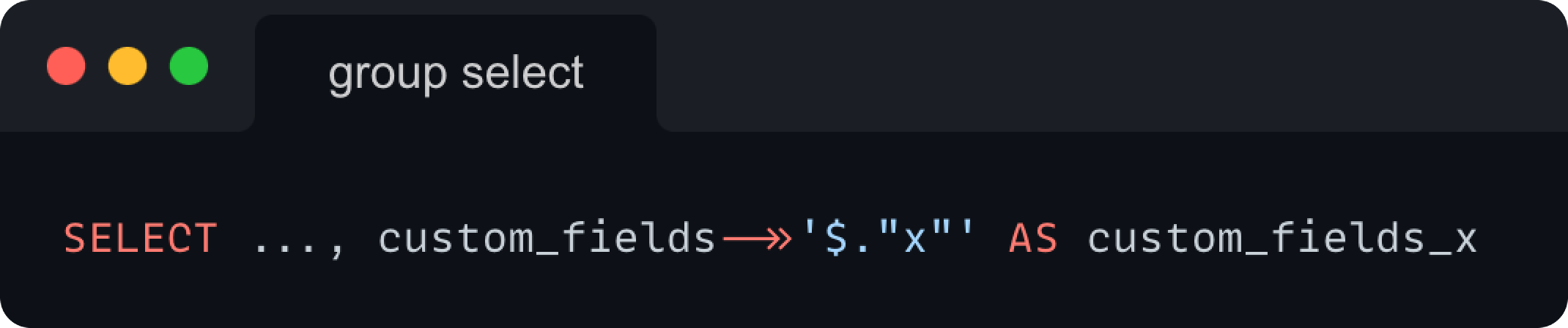
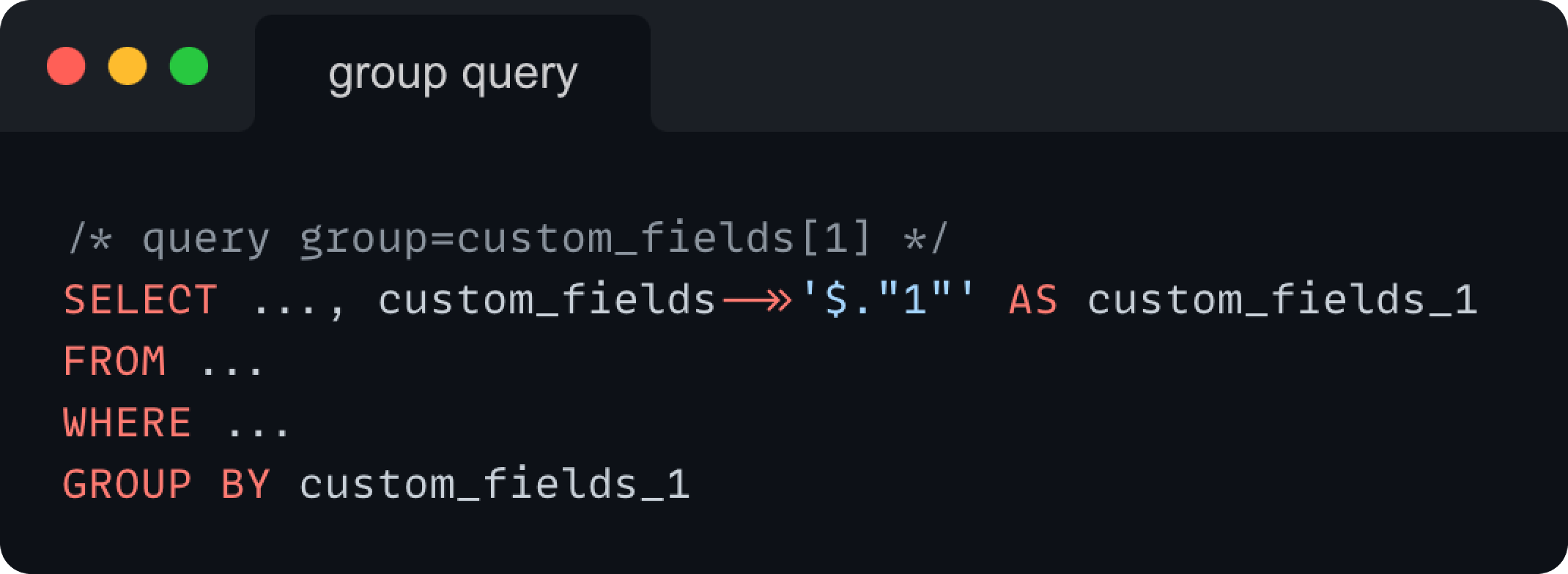
Once we have the virtual column defined, the grouping part gets done simply, by adding the GROUP BY statement with the earlier mentioned alias.
So in the end, you get a SQL query like:
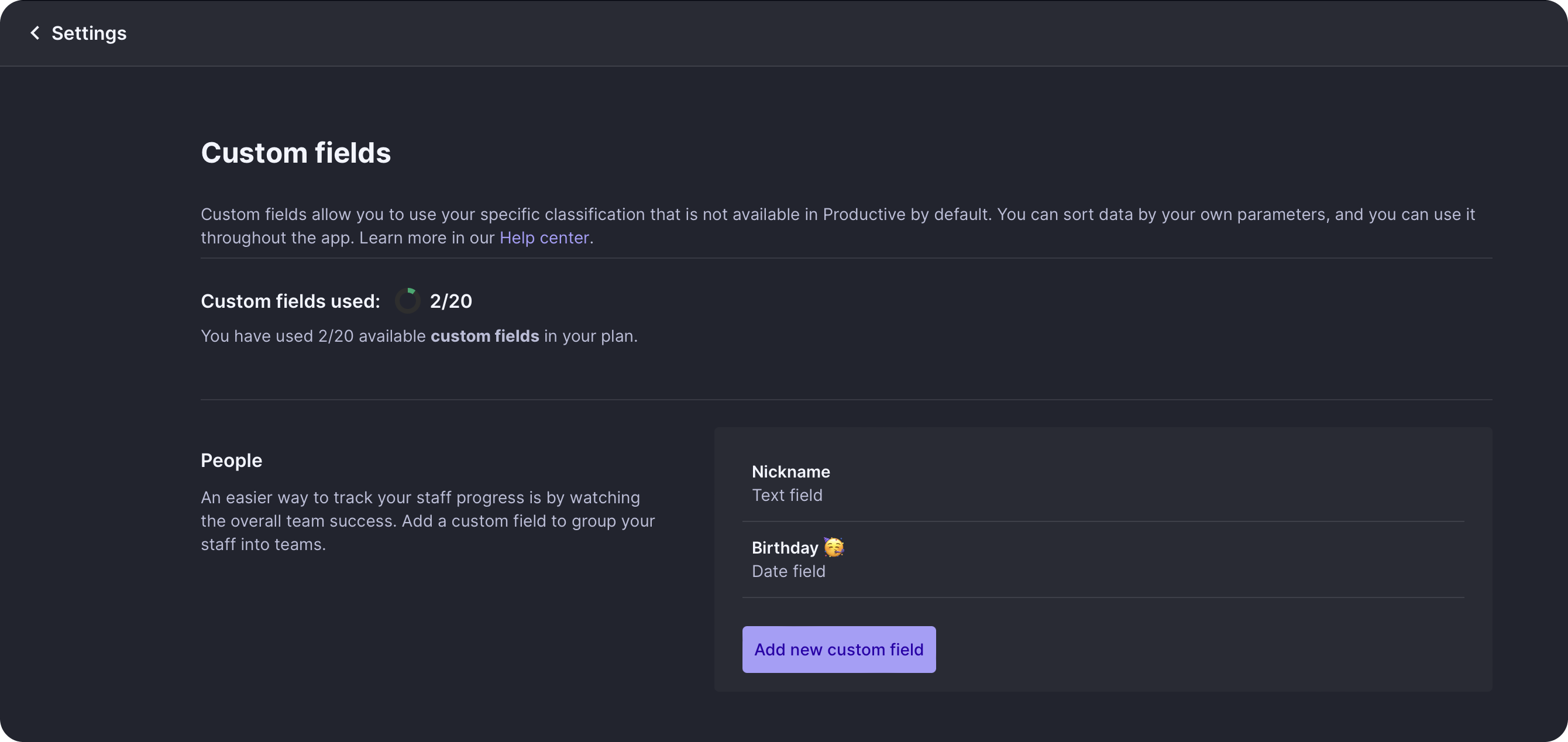
What Our Customers Got
A simple way to define Custom Fields:
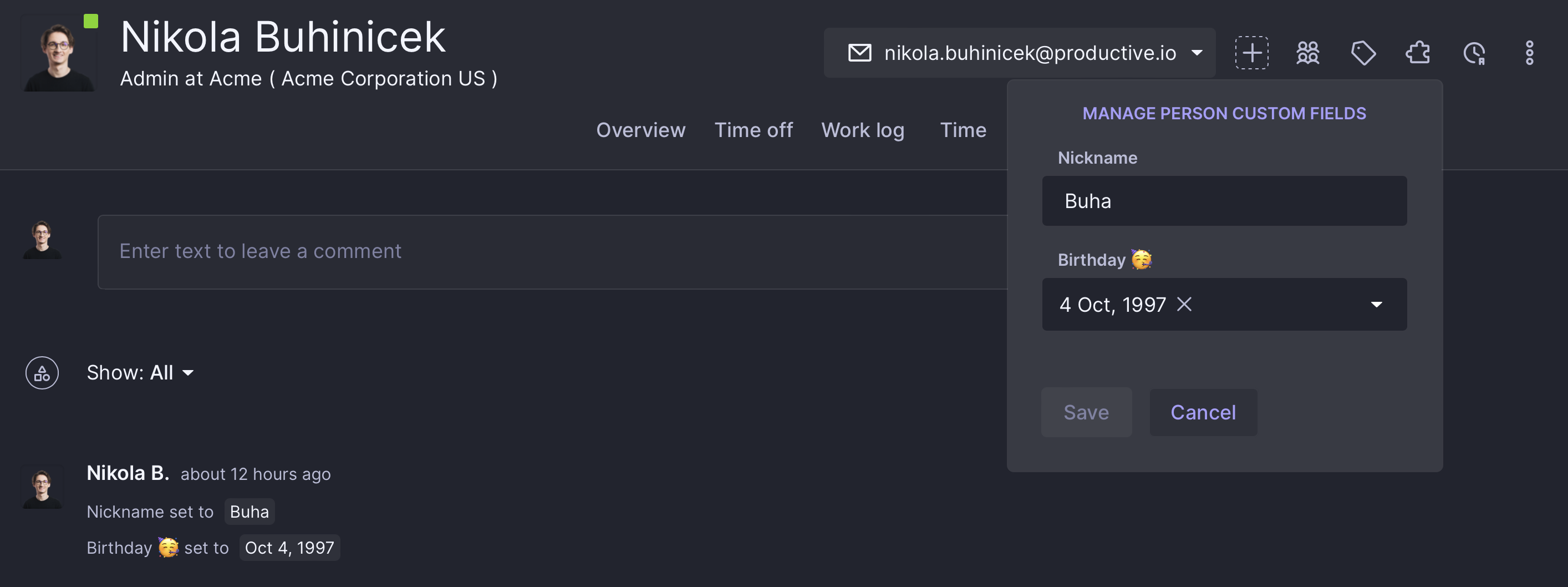
And a place to assign values to their fields:
Summa Summarum
We made it possible for our customers to define custom fields in our data models. Also, we made it possible to search, sort and group by those fields.
It wasn’t long before we had even more requests that built upon our custom fields architecture. The fields we supported at first were okay, but now our customers wanted more field types. They wanted:
- to have dropdown custom fields
- to have relational custom fields
- a field where the values would be objects from one of our existing data models
But before we dig into that, let’s give some time for this basics to sink in. I’ll be back soon with another blog post in which I cover how we solved that new set of feature requests.

